Ray 学习笔记
Ray 学习笔记
Ray 概述
Ray 是一个用于扩展 AI 和 Python 应用程序(如机器学习)的开源统一框架。它提供了并行处理的计算层,因此您无需成为分布式系统专家。Ray 通过以下组件,最小化了运行分布式个体和端到端机器学习工作流的复杂性:
- 为常见的机器学习任务(如数据预处理、分布式训练、超参数调整、强化学习和模型服务)提供可扩展的库。
- 用于并行化和扩展 Python 应用程序的 Pythonic 分布式计算基元。
- 用于与现有工具和基础设施(如 Kubernetes、AWS、GCP 和 Azure)集成和部署 Ray 集群的集成工具和实用程序。
对于数据科学家和机器学习从业者来说,Ray 让您无需基础设施专业知识就能扩展作业:
- 轻松地在多个节点和 GPU 上并行化和分布 ML 工作负载。
- 利用 ML 生态系统,具有原生和可扩展的集成。
对于 ML 平台构建者和 ML 工程师,Ray:
- 提供了创建可扩展且健壮的 ML 平台的计算抽象。
- 提供了简化上手和与更广泛的 ML 生态系统集成的统一 ML API。
- 通过使相同的 Python 代码能够从笔记本电脑无缝扩展到大型集群,减少了开发与生产之间的摩擦。
对于分布式系统工程师,Ray 自动处理关键过程:
- 编排——管理分布式系统的各种组件。
- 调度——协调任务执行的时间和地点。
- 容错——确保任务完成,不管不可避免的故障点。
- 自动扩展——根据动态需求调整分配的资源数量。
Ray 安装
1 | |
Ray 核心组件
Ray Core:提供了一些核心组件构造可扩展的分布式应用
Ray Data:一个可扩展的用户 ML 训练的数据处理库
Ray Train:一个可扩展的 ML 训练库,用于支撑分布式训练以及参数微调
- 可扩展:将模型从单一机器扩展到集群
- 抽象性:忽略了分布式计算的复杂性
- 适用方面:大模型以及大型数据集
Ray Tune:用于参数微调
Ray Serve:一个可扩展的模型服务库,用于构建在线推理 API
Ray RLlib:一个用于强化学习(RL)的库
Ray Clusters:一系列连接着 Ray head node 的 worker 节点,集群可扩展
Ray Core
关键概念
Task:无状态的 Worker
- Ray 允许任意的函数在分离的 python worker 上执行
- 可以明确资源需求(CPUs, GPUs)
Actor:有状态的 Worker
- 可以让函数访问其对应的 worker 的变量
- 也可以明确资源需求
Object:Task 以及 Worker 都是在 Object 上计算的
- 可以在任意的 Ray 集群中存储
- 可以被引用
- 远程 Object 被缓存在 Ray 的分布式共享内存存储中
Placement Groups:允许用户管原子性地管理组资源
- 可以计划 Ray 的 Task 以及 Actor
编程模型
remote 函数
1 | |
./_private/worker.py
1 | |
./_private/worker.py
1 | |
./remote_function.py
1 | |
因此对于 remote 装饰器的请求,其内部流程大体如下
remote函数接收类或者函数作为参数_make_remote函数将其封装为类RemoteFunctionRemoteFunction里头有self.remote属性,存放传入的函数ff.remote调用原来的方法
示例
基于 Task 的批量预测
通过 Ray 的 Task,可以构建一个批处理预测程序,大概分为三个步骤
- 加载模型
- 部署 Ray Task,每一个 Task 包含了模型以及共享的输入数据集
- 每一个 worker 都在被分配的分片上执行预测,并输出结果
假设我们有这样一个简单的模型
1 | |
为每个 worker 分配 Task
1 | |
驱动程序负责管理所有的 Tasks
1 | |
基于 Actor 的批量预测
上述基于 Tasks 的批量预测算法中,每个 Task 必须从驱动节点获取模型才能开启预测,如果模型很大这将是一个很大的开销。我们通过 Ray Actor 的方式,只需要加载一次模型就能够复用
1 | |
构造函数只会在每个 Worker 被调用一次,我们使用 ActorPool 库来接收预测请求
1 | |
思考
- 对于大模型的加载,应当传递的是模型引用而不是模型本身,
ray提供了ray.put(model)传递模型引用
1 | |
Ray Train
- 训练函数:包含了训练逻辑的 Python 代码
- Worker:一个运行了训练函数的进程
- 可扩展配置:对于 Worker 的配置以及计算资源的配置
- 训练器:将上述三个概念打包起来构建一个分布式训练任务

编程模型
Trainer
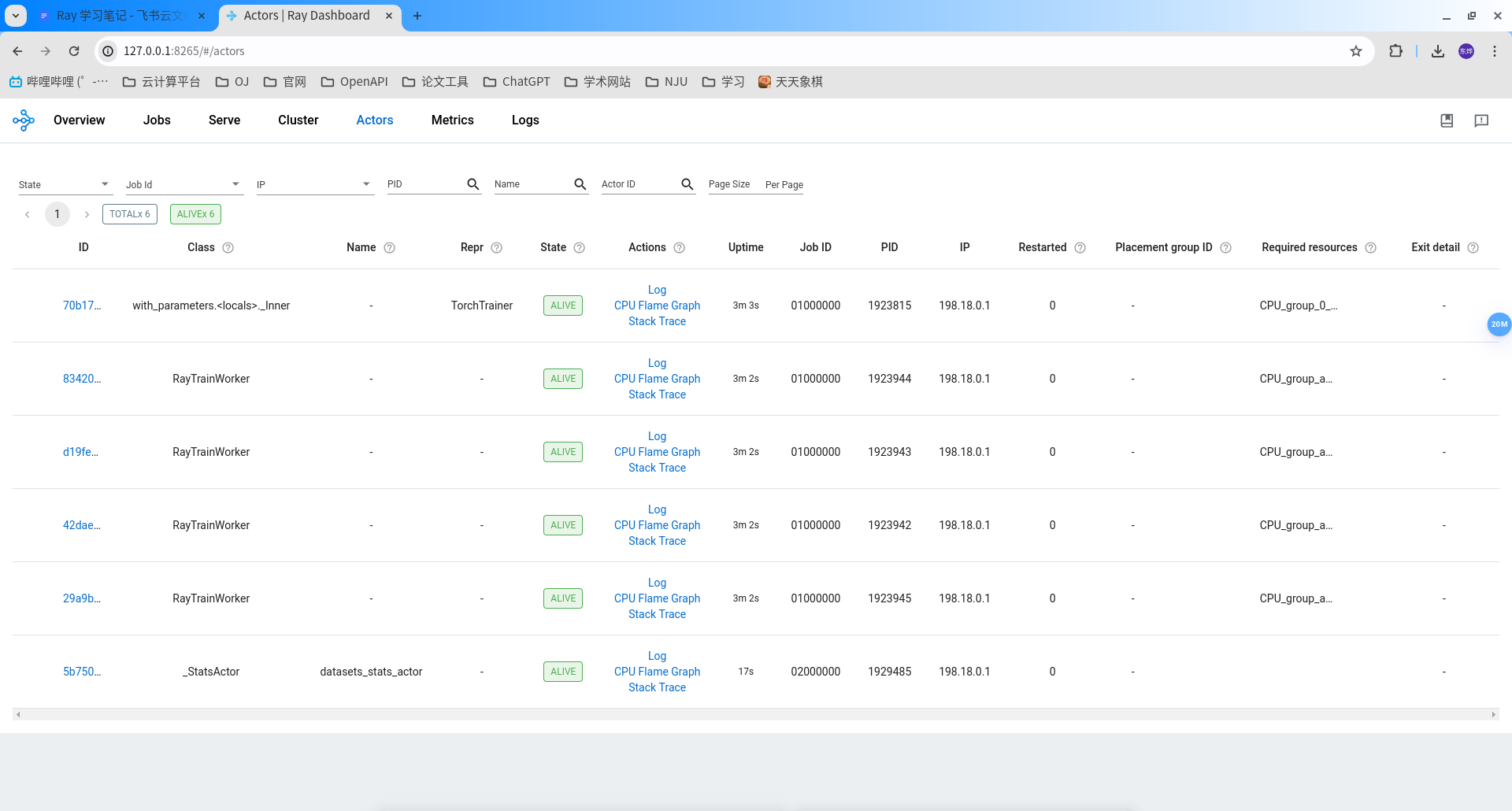
trainer 会构建一个 TorchTriainer,当调用 trainer.fit 的时候,会构建 Actor 自动部署;其实在 dataset 的时候也部署了一个 Actor
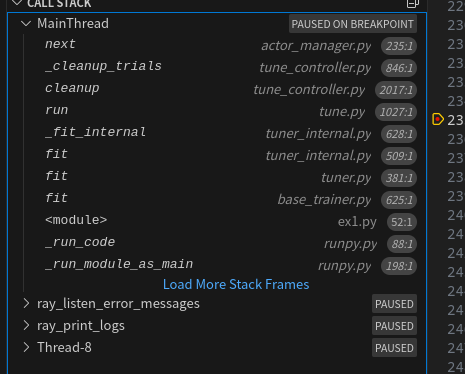
从调用堆栈可以看出,最后会调用到 actor_manager.py。
经过我花费了 2 个小时的分析,其训练器训练函数的大体流程如下:
1 | |
示例
数据加载与预处理
Ray Train 集成了用于数据加载与预处理的库。
数据迁移可以通过以下四个基本步骤执行
- 创建一个 Ray 数据集
- 预处理 Ray 数据集
- 将预处理好的 Ray 数据集输入到 Ray Train 训练器中
- 通过
Train Function消费数据集
1 | |
配置持久化存储
Ray Train 运行会生成报告指标、检查点和其他工件的历史记录。您可以将它们配置为保存到持久存储位置。
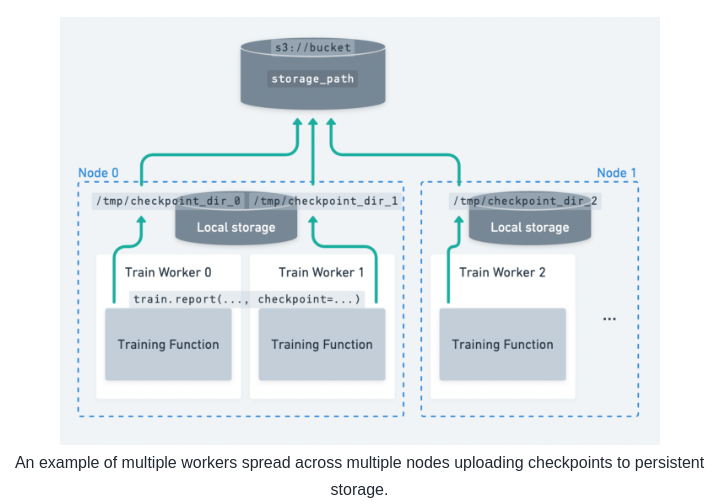
持久化存储能够
- 做标记点以及容错:从持久化存储系统保存标记可以从上一次节点故障的检查点恢复
- 实验后分析:存储所有试验数据的统一位置对于实验后分析非常有用,例如在集群终止后访问最佳检查点和超参数配置
- 通过下游服务和批量推理任务桥接训练/微调:您可以轻松访问模型和工件以与其他人共享或在下游任务中使用它们。
保存加载检查点
Ray Train 提供了一个快照训练过程的进程
- 储存性能最后的模型比重:将模型保存到持久化存储中
- 容错:让长时运行工作从节点错误中恢复
- 分布式检查点:当进行模型并行训练时,Ray Train 检查点提供了一个简单的方法用于更新模型分片,而不是将整个模型集中到单节点
- 与 Ray Tune 集成
MNIST
1 | |
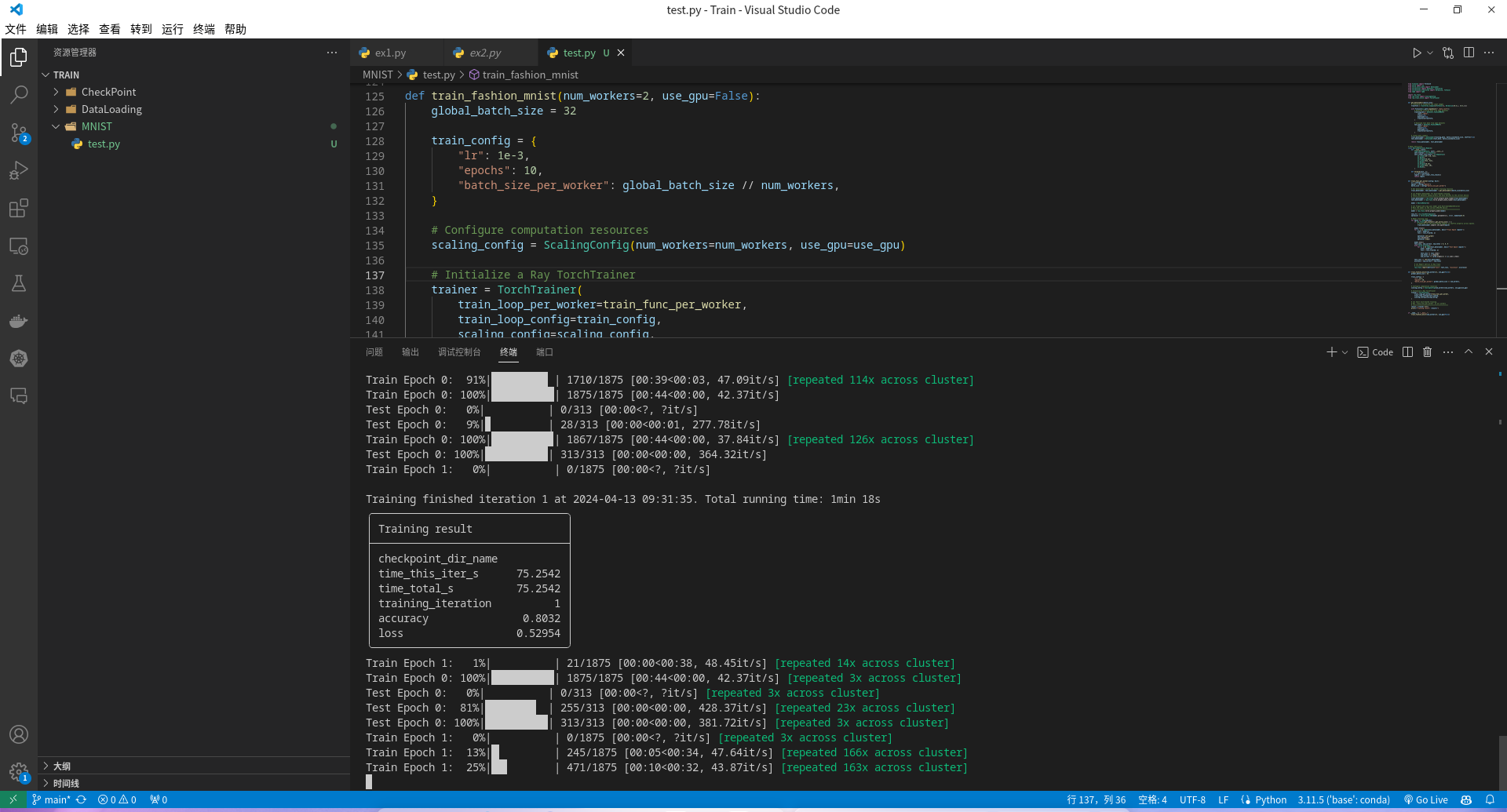
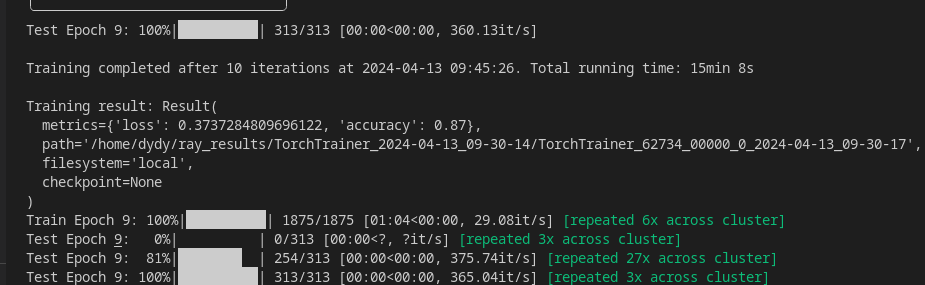
- 机器没有 GPU
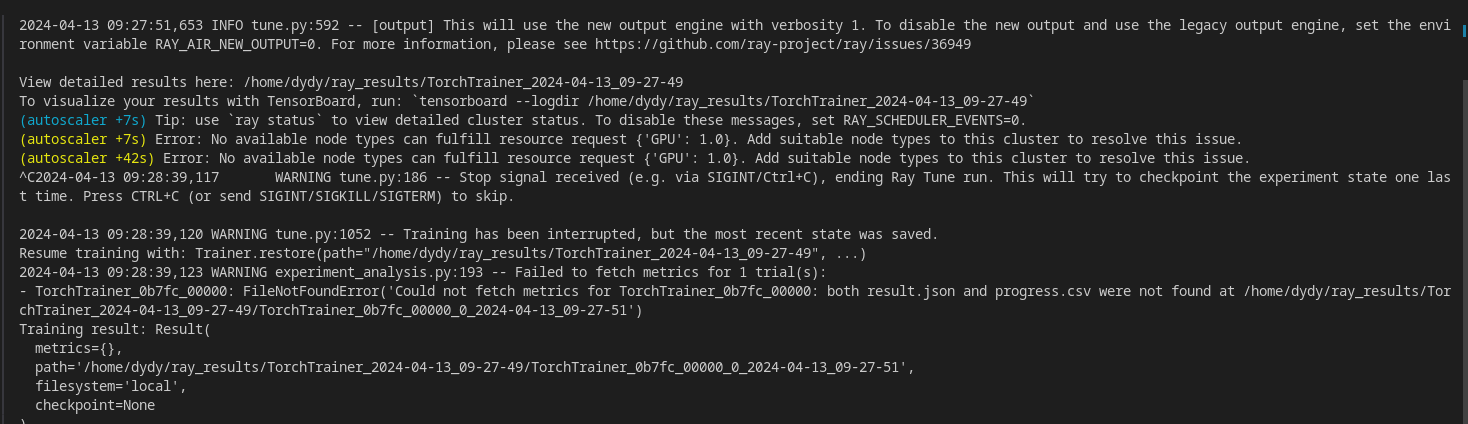
- 使用 CPU


Ray Cluster
核心概念
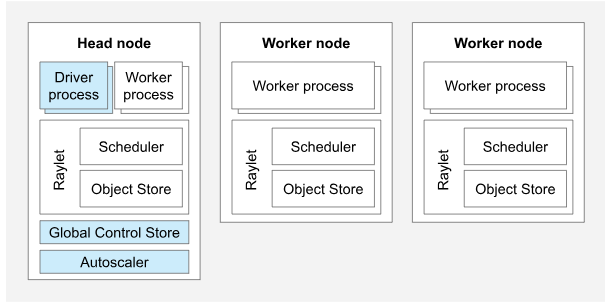
- Ray Cluster: 包含了一个 head 节点以及多个 worker 节点
- head 节点:与 worker 节点不同,它还运行着一个全局控制存储以及自动扩缩容以及驱动进程
- worker 节点:只负责管理 tasks 以及 actors
- Ray autoscaler:运行在 head 节点上的一个进程。当资源需求超过了当前的负载,autoscaler 就会创建新的 worker
- Ray Jobs:一套集合了 task、actor 以及 object 的工作流
部署到 k8s 集群
KubeRay
KubeRay 提供了一个简单的 k8s 操作集合,简化了部署在 k8s 上部署 Ray 的流程,有 3 种自定义资源(CRDs)
RayCluster:KubeRay 全程管理集群的生命周期
RayJob:将一个 Job 提交到集群
RayServce:由两个部分创建起来
- RayCluster
- Ray Serve
Ray Cluster
其实它部署的是 k8s 的一个 service
RayCluster Quickstart — Ray 2.10.0
- 前提:安装 kubectl, helm
Ray 系统架构
全局控制存储(GCS)
GCS 客户端
Accessor
- ActorInfoAccessor:访问 Actor 的信息
- JobInfoAccessor:访问 Job 的信息
- NodeInfoAccessor:访问工作节点的信息
- NodeResourceInfoAccessor:访问工作节点资源的信息
- ErrorInfoAccessor:访问错误信息
- TaskInfoAccessor:访问任务信息
- WorkerInfoAccessor:访问 Worker 的信息
- PlacementGroupInfoAccessor:访问工作组的信息
- InternalKVAccessor:内部 KV 访问
GlobalStateAccessor
GCS 服务端
发布订阅模型
分级部署调度器
分布式对象存储
计算图模型
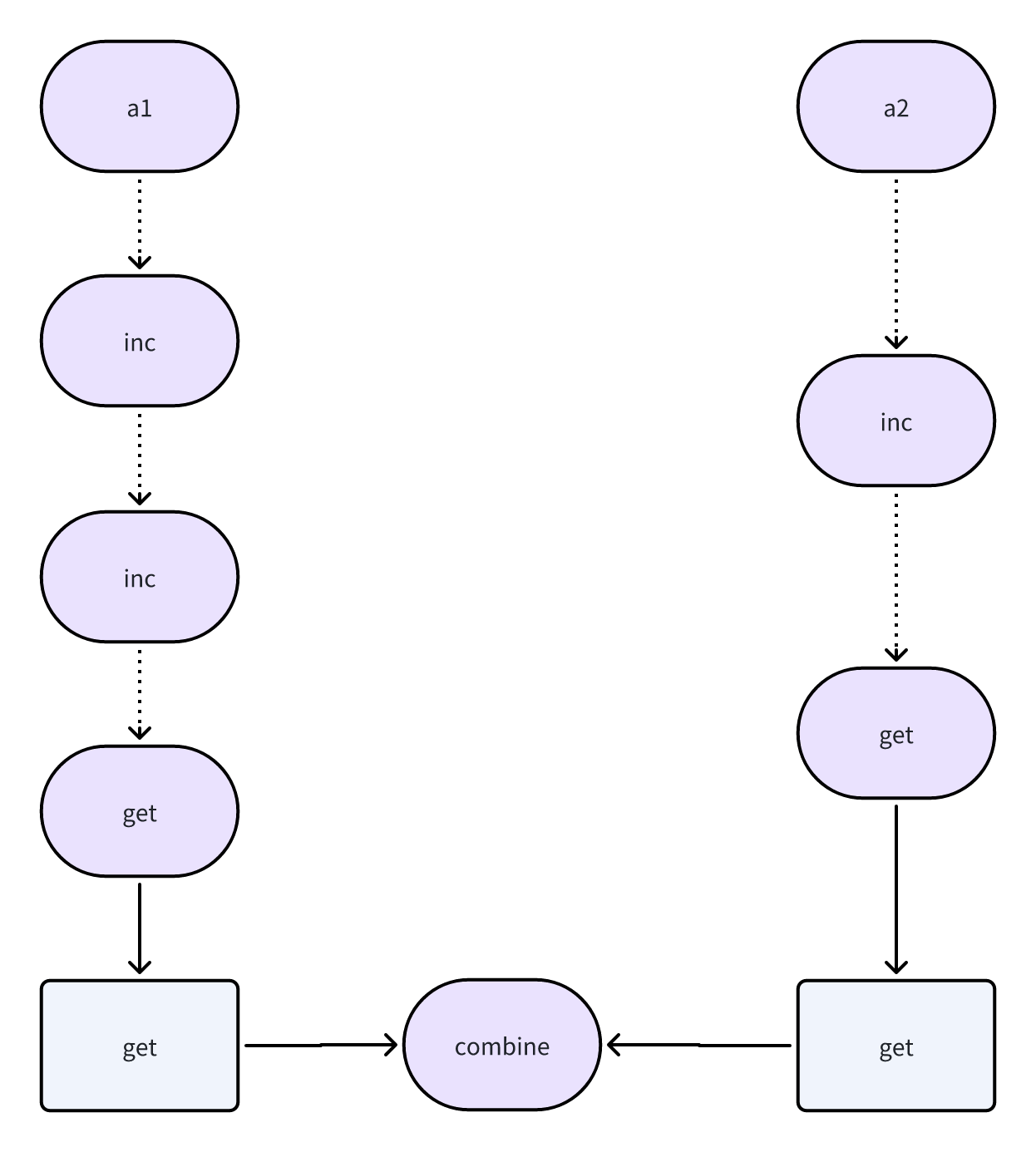
Ray 可以通过构建一张任务图进行计算,相当于定义了一个 Job(workflow),实现任务的并行以及体现任务的依赖关系
注意:Ray 里头所有的参数、数据,都是对象存储,也就是说,他们都是引用!!
图
- 节点
- 数据节点:对象引用,可以给其他任务节点共享
- 任务节点:actor or task
- 边
- 数据边:从任务节点连到数据节点
- 控制边:从任务节点连到任务节点
- 节点
例子
1 | |
1 | |